VGDownloader: Download Any Video Game Soundtrack
VGDownloader is a lightweight CLI that lets you download any* video game soundtrack. Written in Go and built on PromptUI, it pings downloads.khinsider.com to retrieve the album for download. It uses channels and wait groups to concurrently get the download links for every song in the album, downloading them all at the same time. This significantly reduces the amount of time to download the album vs. sequentially downloading from the website.
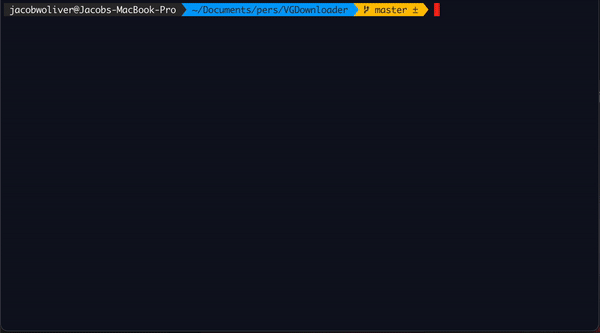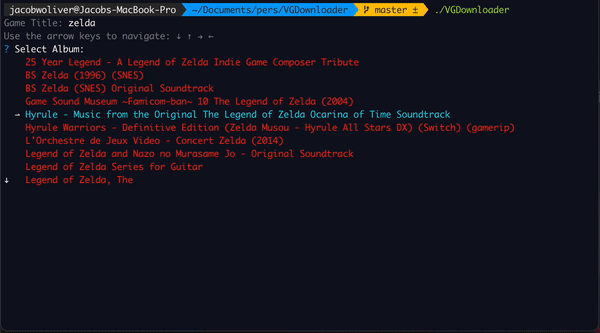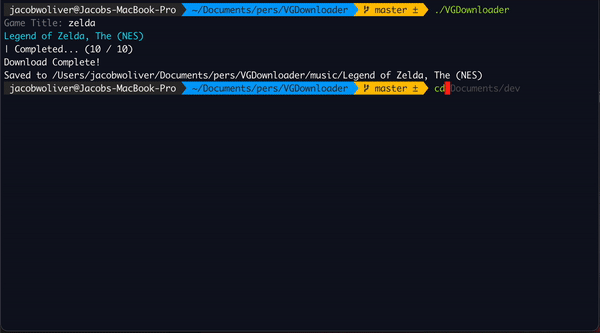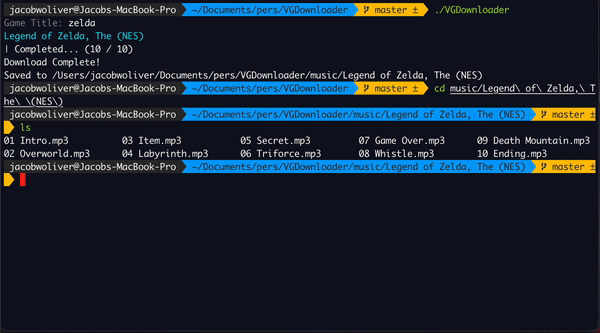
VGDownloader in Action
*The selection is dependent on it being among the 8TB+ of music available on downloads.khinsider.com. Notable omissions include Square Enix soundtracks because the authors asked it to be removed. You can find a complete blacklist here.
Overview
As a broad overview of how VGDownloader works, it will ask the user for an album they want, search for it, then download the songs in the album. Put into a diagram, it looks like this:

VGDownloader Diagram
The important parts to note are identifying which sections need to be sequential (e.g. getting user input) and which can be parallelized. The diagram does a good job at showing when things can be made concurrent and luckily it’s all the cool parts. The Concurrent Downloads section later on will go into more detail of how channels and wait groups are used to speed up the download process.
PromptUI
I wanted to give a little section for PromptUI because I have used it in a few projects and always enjoy working with it. It’s an interactive CLI framework written in Go that makes it really easy to display, filter, and select items from lists all from the terminal. I’ll outline below the few places I found it useful.
Getting the Title of the Game
I’m able to use the interactive CLI by typing in the title of the game I want. To make a prompt with PromptUI, all it takes here is:
func getTitle() (string, error) {
prompt := promptui.Prompt{
Label: "Game Title",
}
title, err := prompt.Run()
if err != nil {
return "", err
}
return title, nil
}
That’s all it takes. That will allow a user to type a string in and return the string, all in a pretty interface.
Search Through Available Albums
Once the title is returned, it calls the site to search for the album, then uses another prompt to display all available options:
func selectAlbum(albumList []reps.AlbumList) (reps.AlbumList, error) {
templates := &promptui.SelectTemplates{
Active: "⇀ {{ .Title | cyan }}",
Inactive: " {{ .Title | red }}",
Selected: "{{ .Title | cyan }}"}
prompt := promptui.Select{
Label: "Select Album",
Items: albumList,
Templates: templates,
Size: 10,
}
index, _, err := prompt.Run()
if err != nil {
return reps.AlbumList{}, err
}
return albumList[index], nil
}
This uses some custom templating to make it look how I want it to, but other than that it is pretty straightforward. You just throw the slice of items into a Select prompt and it will display all of them nicely. You can filter and search through them, then select the one that you want. Once you get the album URL to download from, now it is time to get wacky, wild, and wacky to concurrently download all the tracks.
Concurrent Downloads
The actual cool part of VGDownloader is how it concurrently gets the links to download the files, then conconcurrently downloads the files. Like the diagram above shows, it has to iterate through the HTML to get each download link for each song. Only once it has the link can it download the song. However, getting the link and downloading the song is independent for each song - making this able to be made concurrent.
Channels
A links channel is made to store all song URLs that are scraped from the HTML:
links := make(chan string, 100)
Note: having a buffered channel of 100 isn’t really necessary because the real bottleneck is the downloading of the songs. We just want to make sure that the song links get passed to the function that downloads the songs as fast as possible.
Once the buffered channel is made, it call getSongLinks() in a goroutine:
func getSongLinks(doc *goquery.Document, links chan<- string, total *int) {
doc.Find(".playlistDownloadSong > a").Each(func(i int, s *goquery.Selection) {
link, exist := s.Attr("href")
if exist {
links <- fmt.Sprintf("%s%s", reps.BaseURL, link)
*total += 1
}
})
close(links)
}
This gets the link from the href and passes it into the channel. Once it gets all the links, it will close out the channel. This lets the function reading from the links know when it is all done and ready to go bye-bye.
Wait Groups
Speaking of the function that calls the channel, here it is:
func downloadSongs(links <-chan string, albumName string, total *int) error {
s := reps.NewSpinner("Completed...", total)
wg := new(sync.WaitGroup)
completed := 0
go s.Loading(&completed, total)
for link := range links {
fileName := fmt.Sprintf("%v.mp3", completed)
wg.Add(1)
go downloadSong(wg, link, fileName, albumName, &completed)
}
wg.Wait()
s.Finished()
return nil
}
This creates the sync.WaitGroup and adds to it when it calls downloadSong() in a goroutine. Then it waits until all the downloads are done with wg.Wait(). But how does it know when it’s done? That is achieved in the next function:
func downloadSong(wg *sync.WaitGroup, link string, fileName string, albumName string, completed *int) error {
doc, err := getDocument(link)
if err != nil {
return err
}
encodedUrl, exist := doc.Find("#EchoTopic > p > a[href*='vgmsite']").Eq(0).Attr("href")
if exist {
err = downloadFile(encodedUrl, albumName)
if err != nil {
log.Fatalf("%v\n", err)
}
}
wg.Done()
*completed += 1
return nil
}
downloadSong() will call wg.Done() to let the WaitGroup know that it has finished downloading that song. Since each song is tossed into a goroutine, it will increment the WaitGroup up to the number of total songs in the album, then concurrently decrement as each song finishes. Once the WaitGroup count is 0, that’s when it knows everything has finished downloading.
Performance Comparisons
I thought it’d be fun to throw together some performance testing to see how well this works with varying album sizes. I wanted to test to see how much faster concurrently downloading albums was vs. downloading each song sequentially. To test this, I came up with two different scenarios:
- An album with 10 songs (
4 MBtotal) - An album with 76 songs (
299 MBtotal)
I ran the test 10 times for each album with both scenarios to try to get a good average of the performance. For this test, I made a custom version of VGDownloader that bypasses the PromptUI bits and uses command line arguments to pass in the album URL and whether or not it is concurrent or sequential. It should be noted that the following numbers are obviously dependent on CPU speeds and download rates, but with those things being (relatively) constant on my machine, the numbers are still interesting and useful. Here is the raw output from my tests:
Concurrent - 10 songs (4 MB)
Average after 10 runs: 3.5045613765716555 seconds
Sequential - 10 songs (4 MB)
Average after 10 runs: 7.856122016906738 seconds
Concurrent - 76 songs (299 MB)
Average after 10 runs: 86.71255302429199 seconds
Sequential - 76 songs (299 MB)
Average after 10 runs: 325.70889987945554 seconds
The graph displays the time that it took for each album with sequential and concurrent downloads:
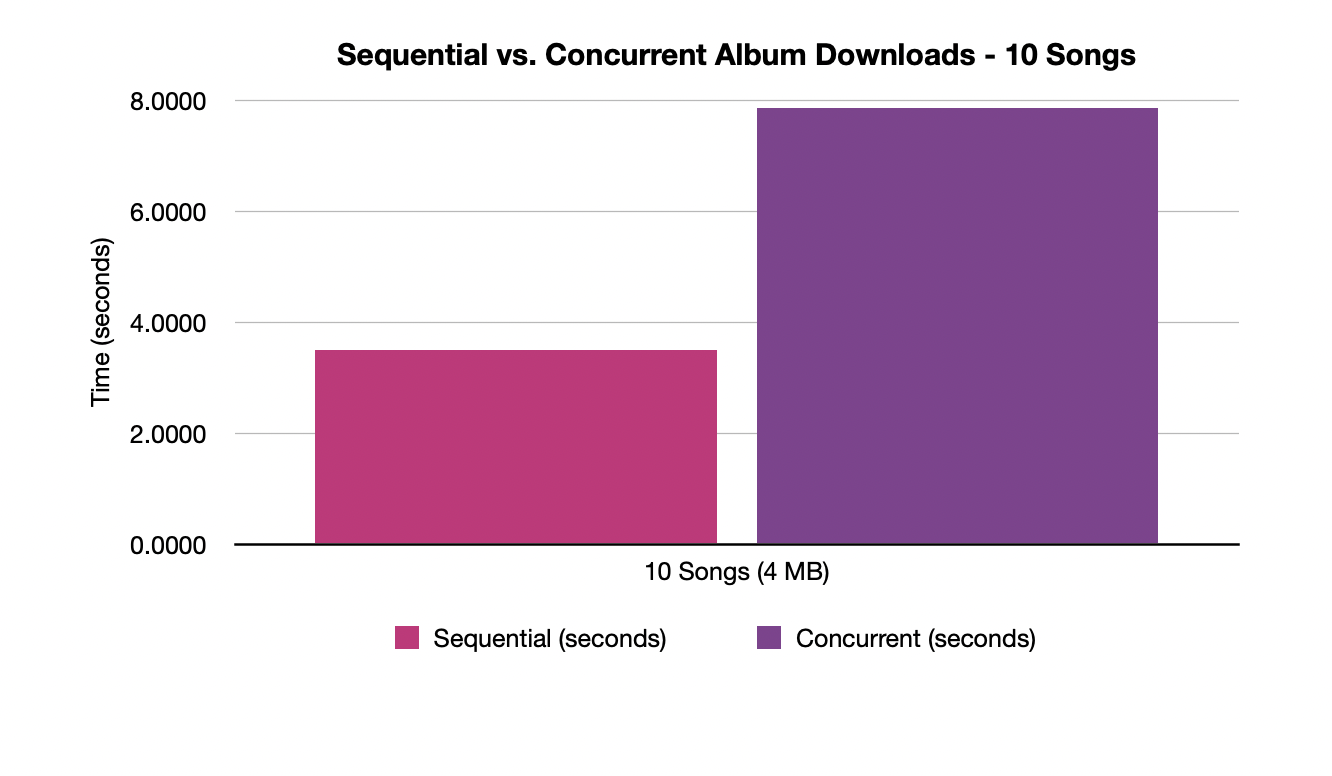
10 Songs Graph
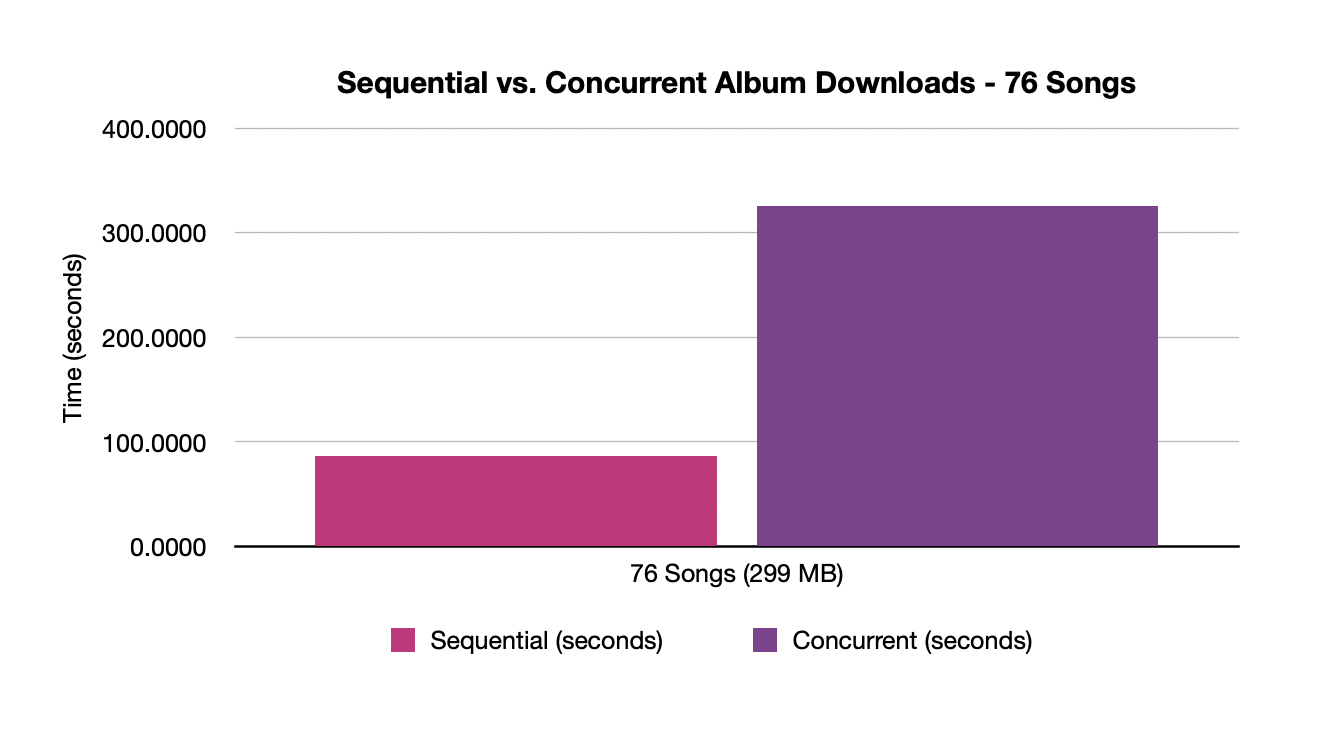
76 Songs Graph
As you can see, the results are pretty apparent. For small albums, downloading the songs concurrently roughly cuts the time in half. The scale of the y-axis is important here though - it takes over 300+ seconds for downloading the large album sequentially, on average. For larger albums, the time savings are even more amplified, leading to nearly a 4x speedup. Downloading 70+ songs really benefits from downloading at the same time because of the benefits of pipelining. When downloading that many songs, it can fetch the links and start downloading as soon as they are available, leading to the bottleneck being the largest files taking longer to finish. But when doing them one at a time, each one has to take its turn, not allowing anything to be done while its waiting.
These results were to be expected, but it was fun to put some numbers to it.
Limitations and Next Steps
Song Naming
My biggest annoyance making this was that you can only get the metadata of the song after it has finished downloading. When I originally made this, I would name the songs 1.mp3, 2.mp3, …, then reopen the file to rename it with the provided metadata. When doing this concurrently, it was causing collisions that made it explode.
I ended up using a worse alternative of getting the name found within the URL. The problem is it’s not always formatted properly, but it gave a simplest solution that was more resilient to breakages.
Another option would be to get the name by scraping the page, but the site doesn’t use consistent ID or class tags in the HTML for the song name (or anything), so it would be difficult to quickly get the name of the song when getting the download link.
No External API
A broader issue is that there is no API so I have to scrape everything. An API would make this much easier and would probably help provide more functionality than what I have. But I’m currently being a vagrant, stealing bandwidth for free from the site, so beggars can’t be choosers I guess.
Miscellaneous
A few other rapid fire things that came up while making this:
- The
getDocument()function feels slow for what it does. I want to see if there is a better/faster way to get the HTML. - I create the output directory with
777permissions… probably not the best. - If there is no album available, it will get some random sidebar content, which is jarring. Would be good to figure out how to know when no albums are available and tell that to the user.
- The site supports both MP3 and FLAC for some albums. It would be nice to add the ability to pass in a
--flacflag. This would download the FLAC version of the songs if they are available. If they are not, then it will default back to MP3.